See https://github.com/slott56/cpx-xmas-ornament
You'll need a Circuit Playground Express https://www.adafruit.com/product/3333
Install the code. Enjoy the noise and blinky lights.
The MML translation isn't as complete as you might like. The upper/lower case for the various commands isn't handled quite as cleanly as it could be. AFAIK, case shouldn't matter, but I omitted any lower() functions, making the MML parser case sensitive. It only mattered for one of the four songs, and it was easier to edit the song.
The processing leaves a great deal of "clickiness" in the start_tone() processing. I think I know how to address it.
There are barely 96 or so different tones available in MML compositions. It might be possible to generate the wave shapes in advance to have a smoother music experience.
One could image having an off-line translator to transform the MML text into a sequence of bytes with note number and duration. This would slightly compress the song, but would speed up processing by eliminating the overhead of parsing.
Additionally, having 96 wave tables could speed up tone production. The tiny bit of time to recompute the sine wave at a given frequency would be eliminated. But. Memory is limited.
Tuesday, December 31, 2019
Tuesday, December 24, 2019
Walrusing Around
This is -- well -- it is what it is. I don't have to like it.
It works and shows how the assignment operator works.
The point here is to convert a timestamp into ISO week, day, hour, minute, second. 13th week, 2nd day, 7h, 53m, 19s.
The divmod() function returns a two-tuple, which the assignment operator can't decompose. Instead, we decompose it by wrapping the whole thing in ()[1].
Works.
Do Not Recommend.
>>> t_s = (8063599, 0) >>> fields = [(t_s := divmod(t_s[0], b))[1] for b in (60, 60, 24, 7)] >>> list(reversed(fields + [t_s[0]])) [13, 2, 7, 53, 19]
It works and shows how the assignment operator works.
The point here is to convert a timestamp into ISO week, day, hour, minute, second. 13th week, 2nd day, 7h, 53m, 19s.
The divmod() function returns a two-tuple, which the assignment operator can't decompose. Instead, we decompose it by wrapping the whole thing in ()[1].
Works.
Do Not Recommend.
Tuesday, December 17, 2019
Plannng a Linked-in Learning Course (and using the := walrus operator)
I've recorded two courses for LinkedIn Learning https://www.linkedin.com/learning/me
Let me emphasize that their production values take a lot of work. While I think I'm a pretty good live presenter, a few days in the recording booth with a producer, reveals all my weaknesses. so. um. you know?
I'm starting down the road to at least one more, maybe another one or two after that.
Which leads to code. Of course. And the code uses the assignment expression ("walrus") operator.
Here's what's going on. I've got a directory full of CSV files with the slide-by-slide scripts. Each file has a bunch of tabs, and the relevant tables have a fixed heading that the production folks use.
target_headings = ['Part', 'Voice', 'Visual Description', 'Storyboard / Description']
The "Voice" column in these tables is the script. Each row is a slide or other visual. The overall management of the resources with all of these spreadsheets doesn't seem ideal to me. However, it's the way skilled professionals prefer to manage these multi-media assets.
The question is: "which sections are too long?"
Generally, we speak at a consistent rate. During rehearsals, I can use my stopwatch to get timing for a particular script. This gives me a seconds/word or words/second rate metric. Given an average rate, and a script, I can predict a likely duration given the text of the script.
The data is in spreadsheets -- generally the root cause of many complications. There's no word-count in Numbers. So. Time to apply Python. (I'm sure someone has a bunch of Excel macros that can do word-counts. Good for you. I don't own a copy of Excel.)
Here's how this shakes out. There are three parts to the analysis, modeling, and applying the model. The first is a functional flattener to turn all of the files and tabs and tables into a single stream of useful rows.
Here's how this starts.
The outermost for statement locates all .csv files. All the rows within a file will belong to a number of sheets and tables within each sheet. The separator is a line with a Sheet: Table string, described by the sheet_table_pattern. The second for statement picks all the rows from a given sheet, looking for the separators.
There are a bunch of irrelevant tables. Hence the tall stack of if-statements. The useful parts of the script all have names that start with 'Table '. Weird, but true. The match.group(2).startswith('Table ') check feels like some casual ad-hoc test and should probably be made more visible and configurable.
Once we've found a table with the right headings, we can iterate over the following rows until we get to a blank line at end-of-table. We accumulate a dictionary, named text, which has the 'Part' and 'Voice' column values as a handy Dict[str, str] mapping.
Note that we're sharing an iterator, the row_iter variable, among two for statements. This is a very handy trick when doing this kind of partitioning. The outermost use of the iterator is rejecting irrelevant rows. The inner use of the iterator is assembling composite objects from a subset of rows, effectively partitioning the raw data.
This *can* be decomposed into separate functions. Further refactoring is left as an exercise for the reader.
Here's the benchmarking to create a model.
For some sample sections, I read through the material in my best NPR professional broadcasting voice. The sums of words and times give us a time-per-word Fraction object. The resulting value is near 31 seconds for 75 words.
I really like using Fraction instead of float for this kind of thing. The data doesn't support even one decimal place of supposed accuracy.
Note that I didn't factor in any slide count. I assumed this is a linear model from words to time. If I was a real scientist I might have tried a bunch of models.
There are three mappings going on here. This makes it a little tricky to create a simple function to map from raw data to something the model can use, then applying the model.
The 'word_count' is a mapping from raw data to one feature. The 'slide_count' is another mapping from raw data to a secondary feature. The 'm' and 's' values represent another mapping from the word_count to the estimated time.
We can hack this around to find another use for the assignment operator. But the following seems insane:
Let's not consider this assignment expression example as particularly helpful. The above turns two simple statements into a mess.
Something like this is an alternative that's slightly more functional.
I'm not sure this is dramatically "better". It isolates some aspects of feature collection and model application. It also harbors a secret inefficiency. The two feature values should be cached to avoid recomputing them.
I'll leave the refactoring for the interested reader.
The durations over > 5:00 (300 seconds) need some rework. That's the actual useful output: the list of scripts with excessive time becomes the queue of content that needs rework.
The question is: "which sections are too long?"
Generally, we speak at a consistent rate. During rehearsals, I can use my stopwatch to get timing for a particular script. This gives me a seconds/word or words/second rate metric. Given an average rate, and a script, I can predict a likely duration given the text of the script.
The data is in spreadsheets -- generally the root cause of many complications. There's no word-count in Numbers. So. Time to apply Python. (I'm sure someone has a bunch of Excel macros that can do word-counts. Good for you. I don't own a copy of Excel.)
Here's how this shakes out. There are three parts to the analysis, modeling, and applying the model. The first is a functional flattener to turn all of the files and tabs and tables into a single stream of useful rows.
The Data Gathering
The essential data gathering has to flatten the relatively complex file/sheet/table structure into something we can extract features from. A sequence of the final text of the scripts is what we want. Each script can be a mapping from the slide label to the voice content. It's this content -- the script text -- where we'll find the interesting features.Here's how this starts.
from pathlib import Path
from fractions import Fraction
import csv
import re
from typing import Tuple, Dict, Iterator, List
sheet_table_pattern = re.compile(f"^(\w+): (.+)$")
target_headings = ['Part', 'Voice', 'Visual Description', 'Storyboard / Description']
def script_iter(source: Path) -> Iterator[Tuple[str, Dict[str, str]]]:
for script_path in sorted(source.glob("*.csv")):
# print(script_path)
with script_path.open() as script_file:
reader = csv.reader(script_file)
row_iter = iter(reader)
for row in row_iter:
if len(row) == 1 and (match := sheet_table_pattern.match(row[0])):
if match and match.group(2).startswith('Table '):
headings = next(row_iter)
if headings == target_headings:
section = match.group(1)
text = {}
# print(f"Analyzing {section}")
for sub_row in row_iter:
if len(sub_row) == 0:
break
dict_sub_row = dict(zip(headings, sub_row))
text[dict_sub_row['Part']] = dict_sub_row['Voice']
yield section, text
The outermost for statement locates all .csv files. All the rows within a file will belong to a number of sheets and tables within each sheet. The separator is a line with a Sheet: Table string, described by the sheet_table_pattern. The second for statement picks all the rows from a given sheet, looking for the separators.
There are a bunch of irrelevant tables. Hence the tall stack of if-statements. The useful parts of the script all have names that start with 'Table '. Weird, but true. The match.group(2).startswith('Table ') check feels like some casual ad-hoc test and should probably be made more visible and configurable.
Once we've found a table with the right headings, we can iterate over the following rows until we get to a blank line at end-of-table. We accumulate a dictionary, named text, which has the 'Part' and 'Voice' column values as a handy Dict[str, str] mapping.
Note that we're sharing an iterator, the row_iter variable, among two for statements. This is a very handy trick when doing this kind of partitioning. The outermost use of the iterator is rejecting irrelevant rows. The inner use of the iterator is assembling composite objects from a subset of rows, effectively partitioning the raw data.
This *can* be decomposed into separate functions. Further refactoring is left as an exercise for the reader.
The Benchmark Data
The result of benchmarking is a Fraction object with my unique reading pace. And yes, a Fraction makes more sense than a float value. We're working in int space, and introducing float seems wrong.Here's the benchmarking to create a model.
def rate() -> Fraction:
Benchmarks = [
{'time': 3*60 + 29, 'words': 568}, # 01_01
{'time': 5*60 + 32, 'words': 732}, # 01_04
{'time': 5*60 + 54, 'words': 985}, # 02_04
{'time': 4*60 + 58, 'words': 663}, # 02_05
{'time': 8*60 + 48, 'words': 1192}, # 03_02 (draft)
]
time_bm = sum(b['time'] for b in Benchmarks)
words_bm = sum(b['words'] for b in Benchmarks)
time_per_word = Fraction(time_bm/words_bm)
return time_per_word
For some sample sections, I read through the material in my best NPR professional broadcasting voice. The sums of words and times give us a time-per-word Fraction object. The resulting value is near 31 seconds for 75 words.
I really like using Fraction instead of float for this kind of thing. The data doesn't support even one decimal place of supposed accuracy.
Note that I didn't factor in any slide count. I assumed this is a linear model from words to time. If I was a real scientist I might have tried a bunch of models.
Applying the Model
The model is linear. It's a scaling factor applied to a specific feature, the number of words. Here's one version of the code. I'm not sure I like it.def main() -> None:
time_per_word = rate()
source = Path.cwd()
print(f"script, slides, words, time")
for script, body in script_iter(source):
word_count = sum(len(text.split()) for text in body.values())
slide_count = sum(1 for text in body.values() if len(text) > 0)
m, s = divmod(int(word_count*time_per_word), 60)
print(f"{script}, {slide_count}, {word_count}, {m}:{s:02d}")
There are three mappings going on here. This makes it a little tricky to create a simple function to map from raw data to something the model can use, then applying the model.
The 'word_count' is a mapping from raw data to one feature. The 'slide_count' is another mapping from raw data to a secondary feature. The 'm' and 's' values represent another mapping from the word_count to the estimated time.
We can hack this around to find another use for the assignment operator. But the following seems insane:
divmod(int(word_count:=sum(len(text.split()) for text in body.values())*time_per_word), 60)
Let's not consider this assignment expression example as particularly helpful. The above turns two simple statements into a mess.
Alternative Implementation
The relationships among the mappings can be built a pure functional programming, but seems flirt with needless complexity. We can have a pair of functions to map the body.values() to some named tuple with feature values. We can use a third function to apply the model.Something like this is an alternative that's slightly more functional.
class Features(NamedTuple):
body: Dict[str, str]
@property
def word_count(self) -> int:
return sum(len(text.split()) for text in self.body.values())
@property
def slide_count(self) -> int:
return sum(1 for text in self.body.values() if len(text) > 0)
def duration(self, time_per_word: Fraction) -> int:
return int(self.word_count*time_per_word)
def main_2() -> None:
time_per_word = rate()
source = Path.cwd()
print(f"script, slides, words, time")
for script, body in script_iter(source):
details = Features(body)
m, s = divmod(details.duration(time_per_word), 60)
print(f"{script}, {details.slide_count}, {details.word_count}, {m}:{s:02d}")
I'm not sure this is dramatically "better". It isolates some aspects of feature collection and model application. It also harbors a secret inefficiency. The two feature values should be cached to avoid recomputing them.
I'll leave the refactoring for the interested reader.
The durations over > 5:00 (300 seconds) need some rework. That's the actual useful output: the list of scripts with excessive time becomes the queue of content that needs rework.
Wednesday, December 4, 2019
Creating Palindromes -- if possible -- from a string of letters.
This can be an interesting exercise. I think it is something that can help people learn to code well. I found this in the LinkedIn Python community: https://www.linkedin.com/groups/25827/.
The Palindrome Problem:
Make a function that makes a palindrome out of the letters in a string and
returns -1 if this is not possible.
Convert a list of strings with the function.
Some test cases:
>>> palify('eedd')
'edde' (or 'deed')
>>> palify('wgerar')
>>> palify('uiuiqii')
'uiiqiiu' or several similar variants.
Let's not get too carried away. I like *some* of this problem.
I don't like the idea of Union[str, int] as a return type from this function. Yes, it's valid Python, but it seems like a code smell. Since the intent is to build lists, a None would be more sensible than a number; we'd have Optional[str] which seems better overall.
The solution that was posted was interesting. It did way too much work, but it was acceptable-looking Python. (It started with a big block comment with "#" on each line instead of a docstring, so... there were minor style problems, but otherwise, it was not bad.)
Here's what popped into my head, to act as a concrete response to the request for comments.
"""
Make a function that makes a palindrome out of the letters in a string and
returns -1 if this is not possible.
Convert a list of strings with the function.
Some test cases:
>>> palify('eedd')
'edde'
>>> palify('wgerar')
>>> palify('uiuiqii')
'uiiqiiu'
"""
from typing import Optional, Set
def palify(source: str) -> Optional[str]:
"""Core palindromic conversion."""
singletons: Set[str] = set()
pairs = list()
for c in source:
if c in singletons:
pairs.append(c)
singletons.remove(c)
else:
singletons.add(c)
if pairs and len(singletons) <= 1:
# presuming a single letter can't be palindromic.
return ''.join(pairs+list(singletons)+pairs[::-1])
return None
if __name__ == "__main__":
s = ['eedd', 'wgerar', 'uiuiqii']
p = list(map(palify, s))
print(f"from {s=}, we get {p=}")
The core problem statement is interesting. And the ancillary requirement is almost as interesting as the problem.
The simple-seeming "Make a palindrome out of the letters of the string" has two parts. First, there's the question of "can it even become a palindrome"? Which implies validating the source data against some set of rules. After that, we have to emit one of the many possible palindromes from the source material.
The original post had a complicated survey of the data. This was followed by an elegant way of creating a palindrome from the survey data. Since we're looking for a bunch of pairs and a singleton, I elided the more complex survey and opted to collect pairs and singletons into two separate collections.
When we've consumed the input, we will have partitioned the characters into their two pools and we can decide if the pools have the right sizes to proceed. The emission of the palindrome is a lazy assembly of the resulting data, first as a list, and then transformed to a single string.
The ancillary requirement is interesting in its own right. When a bundle of letters can't form a palindrome, that seems like a ValueError exception to me. Doing bulk transformations in the presence of ValueErrors seems wrong-ish. I already griefed about the -1 response above: it seems very bad. A None is less bad than -1. An Exception, however, seems like a more right thing to do.
Code Review Response
I think my response to the original code should be follow-up questions on why a defaultdict(int) was used to survey the data in the first place. A Counter() is a better idea, and requires less code.The survey involved trying to locate singletons -- a laudable goal. There may have been a better approach to looking for the presence of a singleton letter in the Counter values.
More fundamentally, there are few states for each letter. There are two stark algorithmic choices: a structure keyed by letter or collections of letters. I've shown the collections, and hinted at the collection. The student response used a collection.
I think this problem serves as a good discussion for algorithmic alternatives. The core problem of detecting the possibility of palindromicity for a bunch of letters is cool. There are two choices. The handling of the exceptional case (-1, None or ValueError) is another bundle of choices.
Tuesday, December 3, 2019
Functional programming design pattern: Nested Iterators == Flattening
Here's a functional programming design pattern I uncovered. This may not be news to you, but it was a surprise to me. It cropped up when looking at something that needs parallelization to reduced the elapsed run time.
Consider this data collection process.
Consider this data collection process.
for h in some_high_level_collection(arg1):
for l in h.some_low_level_collection(arg2):
if some_filter(l):
logger.info("Processing %s %s", h, l)
some_function(h, l)
This is pretty common in devops world. You might be looking at all repositories in all github organizations. You might be looking at all keys in all AWS S3 buckets under a specific account. You might be looking at all tables owned by all schemas in a database.
It's helpful -- for the moment -- to stay away from taller tree structures like the file system. Traversing the file system involves recursion, and the pattern is slightly different there. We'll get to it, but what made this clear to me was a "simpler" walk through a two-layer hierarchy.
The nested for-statements aren't really ideal. We can't apply any itertools techniques here. We can't trivially change this to a multiprocessing.map().
In fact, the more we look at this, the worse it is.
Here's something that's a little easier to work with:
Here's something that's a little easier to work with:
def h_l_iter(arg1, arg2):
for h in some_high_level_collection(arg1):
for l in h.some_low_level_collection(arg2):
if some_filter(l):
logger.info("Processing %s %s", h, l)
yield h, l
itertools.starmap(some_function, h_l_iter(arg1, arg2))
The data gathering has expanded to a few more lines of code. It gained a lot of flexibility. Once we have something that can be used with starmap, it can also be used with other itertools functions to do additional processing steps without breaking the loops into horrible pieces.
I think the pattern here is a kind of "Flattened Map" transformation. The initial design, with nested loops wrapping a process wasn't a good plan. A better plan is to think of the nested loops as a way to flatten the two tiers of the hierarchy into a single iterator. Then a mapping can be applied to process each item from that flat iterator.
I think the pattern here is a kind of "Flattened Map" transformation. The initial design, with nested loops wrapping a process wasn't a good plan. A better plan is to think of the nested loops as a way to flatten the two tiers of the hierarchy into a single iterator. Then a mapping can be applied to process each item from that flat iterator.
Extracting the Filter
We can now tease apart the nested loops to expose the filter. In the version above, the body of the h_l_iter() function binds log-writing with the yield. If we take those two apart, we gain the flexibility of being able to change the filter (or the logging) without an awfully complex rewrite.T = TypeVar('T')
def logging_iter(source: Iterable[T]) -> Iterator[T]:
for item in source:
logger.info("Processing %s", item)
yield item
def h_l_iter(arg1, arg2):
for h in some_high_level_collection(arg1):
for l in h.some_low_level_collection(arg2):
yield h, l
raw_data = h_l_iter(arg1, arg2)
filtered_subset = logging_iter(filter(some_filter, raw_data))
itertools.starmap(some_function, filtered_subset)
Yes, this is still longer, but all of the details are now exposed in a way that lets me change filters without further breakage.
Now, I can introduce various forms of multiprocessing to improve concurrency.
This transformed a hard-wired set of nest loops, if, and function evaluation into a "Flattener" that can be combined with off-the shelf filtering and mapping functions.
I've snuck in a kind of "tee" operation that writes an iterable sequence to a log. This can be injected at any point in the processing.
Logging the entire "item" value isn't really a great idea. Another mapping is required to create sensible log messages from each item. I've left that out to keep this exposition more focused.
Now, I can introduce various forms of multiprocessing to improve concurrency.
This transformed a hard-wired set of nest loops, if, and function evaluation into a "Flattener" that can be combined with off-the shelf filtering and mapping functions.
I've snuck in a kind of "tee" operation that writes an iterable sequence to a log. This can be injected at any point in the processing.
Logging the entire "item" value isn't really a great idea. Another mapping is required to create sensible log messages from each item. I've left that out to keep this exposition more focused.
I'm sure others have seen this pattern, but it was eye-opening to me.
This simplification doesn't add much value, but it seems to be general truth. In Python, it's a small change in syntax and therefore, an easy optimization to make.
Full Flattening
The h_l_iter() function is actually a generator expression. A function isn't needed.h_l_iter = (
(h, l)
for h in some_high_level_collection(arg1)
for l in h.some_low_level_collection(arg2)
)
This simplification doesn't add much value, but it seems to be general truth. In Python, it's a small change in syntax and therefore, an easy optimization to make.
What About The File System?
When we're working with some a more deeply-nested structure, like the File System, we'll make a small change. We'll replace the h_l_iter() function with a recursive_walk() function.
def recursive_walk(path: Path) -> Iterator[Path]:
for item in path.glob():
if item.is_file():
yield item
elif item.is_dir():
yield from recursive_walk(item)
This function has, effectively the same signature as h_l_iter(). It walks a complex structure yielding a flat sequence of items. The other functions used for filtering, logging, and processing don't change, allowing us to build new features from various combinations of these functions.
This pattern works for simple, flat items, nested structures, and even recursively-defined trees. It introduces flexibility with no real cost.
The other pattern in play is:
These felt like blinding revelations to me.
tl;dr
The too-long version of this is:
Replace for item in iter: process(item) with map(process, iter).
This pattern works for simple, flat items, nested structures, and even recursively-defined trees. It introduces flexibility with no real cost.
The other pattern in play is:
Any for item in iter: for sub-item in item: processing is "flattening" a hierarchy into a sequence. Replace it with (sub-item for item in iter for sub-item in item).
These felt like blinding revelations to me.
Tuesday, November 26, 2019
Refactoring
Follow my Patreon: Become a Patron!
I'll try to focus on my Building Skills in OO Design book there. I'm thinking of adding some more code examples. Is that a good idea?
Maybe that should be the higher-level Patreon benefit?
I'll try to focus on my Building Skills in OO Design book there. I'm thinking of adding some more code examples. Is that a good idea?
Maybe that should be the higher-level Patreon benefit?
Tuesday, November 19, 2019
Python 3.8 features
 | Real Python (@realpython) |
|
📺🐍 Cool New Features in Python 3.8
realpython.com/courses/cool-n… | |
I'm learning a lot about my previously sketchy designs and potential problems with some of them. There are a number of things in Python which "work" in a vague hand-wavey way. But they don't work in a "I can convince mypy this will work" way.
The additional "convince mypy" rigor can separate potentially sketchy design from an unassailable design.
Tuesday, November 12, 2019
Python 2 Remediation
https://medium.com/capital-one-tech/python-2-remediation-and-problems-at-sea-a58e805d6468
We're about out of time for this effort.
We're about out of time for this effort.
Tuesday, October 29, 2019
Building Skills in OO Design
See https://www.patreon.com/posts/30995708
I've (finally) gotten the book content upgraded to Python 3.7.
I've also deleted all the previous versions of the book. I had been keeping them on my web server because -- well -- because I don't know why. They go back to at least 2011, some of the content may be even older than that.
I've also deleted some previous self-published content.
(I started writing about Python almost 20 years ago. Some of the content could have been that old. It deserves to be deleted.)
I've (finally) gotten the book content upgraded to Python 3.7.
I've also deleted all the previous versions of the book. I had been keeping them on my web server because -- well -- because I don't know why. They go back to at least 2011, some of the content may be even older than that.
I've also deleted some previous self-published content.
(I started writing about Python almost 20 years ago. Some of the content could have been that old. It deserves to be deleted.)
Tuesday, October 22, 2019
State Change and NoSQL Databases
Let's take another look at F. L. Stevens spreadsheet with agencies and agents. It's -- of course -- an unholy mess. Why? It's difficult to handle state change and deduplication.
Let's look at state changes.
The author needs URL's and names and a list of genres the agent is interested in. This is more-or-less static data. It changes rarely. What changes more often is an agent being closed or open to queries.
Another state change is the query itself. Once the email has been sent, the agent (and their agency) should not be bothered again for at least sixty days. After an explicit rejection, there's little point in making any contact with the agent; they're effectively out of the market for a given manuscript.
There are some other stateful rules, we don't need all the details to see the potential complexities here.
A spreadsheet presents a particularly odious non-solution to the problem of state and state change. There's a good and a bad. Mostly bad.
We can try to spread history down the rows of a column. Wow this is bad. We can try to use the hierarchy features to make history a bunch of folded-up details underneath a heading row. This is microscopically better, but still difficult to manage with all the unfolding and folding required to change state after a rejection.
We can blow up a single cell to have non-atomic data -- all of the history with events and dates in a long, ";" delimited list.
There's no good way to represent this in a spreadsheet.
The rigidity of the SQL schema is a barrier here. We're dealing with some sloppy data handling practices in the legacy spreadsheet. We don't want to have to tweak the SQL each time we find some new subtlety that's poorly represented in the spreadsheet data.
We're also handling a number of data sources, each with a unique schema. We need a way to unify these flexibly, so we can fold in additional data sources, once the broken spreadsheet is behind us.
(There are a yet more problems with the relational model in general, those are material for a separate blog post. For now, the rigidity and complexity are a big enough pair of problems.)
We have an Agency as the primary document., Within an Agency, there are a number of individual Agents. Within each agent is a series of Events. Some Agents aren't even interested in the genre F. L. Stevens writes, so they're closed. Some Agents are temporarily closed. The rest are open.
The author can get a list of open agents, following a number of rules, including waiting after the last contact, and avoiding working with multiple agents within a single agency. After sending query letters, the event history gets an entry, and those agents are in another state, query pending.
One common complaint I hear about a document store is the "cost" of updating a large-ish document. The implicit assumption seems to be that an update operation can't locate the relevant sub-document, and can't make incremental changes. Having worked with both SQL and NoSQL, this "cost of document update" seems to be unmeasurably small.
Another cluster command question hovers around locking and concurrency. Most of them nonsensical because they come from the world of fragmented data in a SQL database. When the relevant object (i.e. Agency) is spread over a lot of rows of several tables, locking is essential. When the relevant object is a single document, locks aren't as important. If two people are updating the same document at the same time, that's a document design issue, or a control issue in the application.
Finally, there are questions about "update anomalies." This is a sensible question. In the relational world, we often have shared "lookup" data. A single change to a lookup row will have a ripple effect to all rows using the lookup row's foreign key.
Think of changing zip code 12345 from Schenectady, NY to Scotia, NY. Everyone sharing the foreign key reference via the zip code has been moved with a single update. Except, of course, nothing is visible until a query reconstructs the desired document from the fragmented pieces.
We've traded a rare sweeping updated across many documents for a sweeping, complex join operating to build the relevant document from the normalized pieces. Queries are expensive, complex, and often wrong. They're so painful, we use ORM's to mask the queries and give us the documents we wanted all along.
We have three classes here. Agency is the parent document. Each Agency contains one or more Agent instances. Each Agent contains one or more Events.
When we fetch an agent's data, we fetch the entire agency, since the "business" rules preclude querying more than one agent in an agency. The queries involve a nuanced state change: a rejection by one agent, opens another in the same agency. Rather than do some additional SQL queries to locate the parent and other children of the parent, just read the whole thing at once.
In later posts, we'll look at deduplication and some other processing. But this seems to be all the schema we'll ever need. The type hints provided mypy some evidence of what we intend to do with these documents.
Let's look at state changes.
The author needs URL's and names and a list of genres the agent is interested in. This is more-or-less static data. It changes rarely. What changes more often is an agent being closed or open to queries.
Another state change is the query itself. Once the email has been sent, the agent (and their agency) should not be bothered again for at least sixty days. After an explicit rejection, there's little point in making any contact with the agent; they're effectively out of the market for a given manuscript.
There are some other stateful rules, we don't need all the details to see the potential complexities here.
A spreadsheet presents a particularly odious non-solution to the problem of state and state change. There's a good and a bad. Mostly bad.
- On the good side, you can edit a single cell, changing the state. You can define a drop-down list of states, or radio buttons with alternative states.
- The be bad side, you're often limited to editing a single cell when you want to change the state. You want to have dates filled in automatically on state change. You want history of state changes. Excel hackers try to write macros to automate filling in the date. History, however... History is a problem.
We can try to spread history down the rows of a column. Wow this is bad. We can try to use the hierarchy features to make history a bunch of folded-up details underneath a heading row. This is microscopically better, but still difficult to manage with all the unfolding and folding required to change state after a rejection.
We can blow up a single cell to have non-atomic data -- all of the history with events and dates in a long, ";" delimited list.
There's no good way to represent this in a spreadsheet.
What to do?
The relational database people love the master-detail relationship. Agency has Agent. Agent has History. The history is a bunch of rows in the history table, with a foreign key relationship with the agent.The rigidity of the SQL schema is a barrier here. We're dealing with some sloppy data handling practices in the legacy spreadsheet. We don't want to have to tweak the SQL each time we find some new subtlety that's poorly represented in the spreadsheet data.
We're also handling a number of data sources, each with a unique schema. We need a way to unify these flexibly, so we can fold in additional data sources, once the broken spreadsheet is behind us.
(There are a yet more problems with the relational model in general, those are material for a separate blog post. For now, the rigidity and complexity are a big enough pair of problems.)
SQL is Out. What Else?
A document store is pretty nice for this. The rest of this section is an indictment of SQL. Feel free to skip it. It's widely known, and well supported elsewhere.We have an Agency as the primary document., Within an Agency, there are a number of individual Agents. Within each agent is a series of Events. Some Agents aren't even interested in the genre F. L. Stevens writes, so they're closed. Some Agents are temporarily closed. The rest are open.
The author can get a list of open agents, following a number of rules, including waiting after the last contact, and avoiding working with multiple agents within a single agency. After sending query letters, the event history gets an entry, and those agents are in another state, query pending.
One common complaint I hear about a document store is the "cost" of updating a large-ish document. The implicit assumption seems to be that an update operation can't locate the relevant sub-document, and can't make incremental changes. Having worked with both SQL and NoSQL, this "cost of document update" seems to be unmeasurably small.
Another cluster command question hovers around locking and concurrency. Most of them nonsensical because they come from the world of fragmented data in a SQL database. When the relevant object (i.e. Agency) is spread over a lot of rows of several tables, locking is essential. When the relevant object is a single document, locks aren't as important. If two people are updating the same document at the same time, that's a document design issue, or a control issue in the application.
Finally, there are questions about "update anomalies." This is a sensible question. In the relational world, we often have shared "lookup" data. A single change to a lookup row will have a ripple effect to all rows using the lookup row's foreign key.
Think of changing zip code 12345 from Schenectady, NY to Scotia, NY. Everyone sharing the foreign key reference via the zip code has been moved with a single update. Except, of course, nothing is visible until a query reconstructs the desired document from the fragmented pieces.
We've traded a rare sweeping updated across many documents for a sweeping, complex join operating to build the relevant document from the normalized pieces. Queries are expensive, complex, and often wrong. They're so painful, we use ORM's to mask the queries and give us the documents we wanted all along.
What's It Look Like?
This:@dataclass
class Agency:
"""A collection of individual agents."""
name : str
url : Optional[str] = field(default=None)
agents : Dict[str, 'Agent'] = field(init=False, default_factory=dict)
@dataclass
class Agent:
"""An Agent with a sequence of events: actions and state changes."""
name : str
url : str
email : str
fiction_genres : List[str]
query_details : str = field(default_factory=str)
events : List['Event'] = field(init=False, default_factory=list)
@dataclass
class Event:
"""An action or state change.
status = 'open', 'closed', 'query sent', 'query outcome', 'closed until', etc.
Depending on the status, there may be additional details.
For 'query sent', there's 'date'.
For 'query outcome', there's 'outcome' and an optional 'date'.
for 'closed until', there's 'reason' and an optional 'date'.
"""
status : str
date : Optional[datetime.date] = field(default=None)
outcome : Optional[str] = field(default=None)
reason : Optional[str] = field(default=None)
def __repr__(self):
return f"{self.status} {self.date} {self.outcome} {self.reason}"
We have three classes here. Agency is the parent document. Each Agency contains one or more Agent instances. Each Agent contains one or more Events.
When we fetch an agent's data, we fetch the entire agency, since the "business" rules preclude querying more than one agent in an agency. The queries involve a nuanced state change: a rejection by one agent, opens another in the same agency. Rather than do some additional SQL queries to locate the parent and other children of the parent, just read the whole thing at once.
In later posts, we'll look at deduplication and some other processing. But this seems to be all the schema we'll ever need. The type hints provided mypy some evidence of what we intend to do with these documents.
Tuesday, October 15, 2019
Apple's Numbers and the All-in-One CSV export
Author F. L. Stevens has a hellishly complex (and irregular) spreadsheet with agents, agencies, and query status. (This is how fiction gets marketed: querying agents.) The spreadsheet has become unmanageably complex, with multiple pages. Each page has multiple tables. Buried in this are three "interesting" tables with agent query information.
Can we talk about drama? There is the dark night of the soul for anyone interested in regular, normalized data.
We have some fundamental choices for working with this mess:
The prefix is a line with "Sheet: Table" Yes. There's a ": " (colon space) separator. The suffix is a simple blank line, essentially indistinguishable from a blank line within a table.
If the table was originally in strict first normal form (1NF) each row would have the same number of commas. If cells are merged, however, the number of commas can be fewer. This makes it potentially difficult to distinguish blank rows in a table from blank lines between tables.
It's generally easiest to ignore the blank lines entirely. We can distinguish table headers because they're a single cell with a sheet: table format. We are left hoping there aren't any tables that have values that have this format.
We have two ways to walk through the values:
Clearly, this is craziness.
Flattening is much nicer.
This provides a relatively simple way to find the relevant tables and sheets. We can use something as simple as the following to locate the relevant data.
This lets us write pleasant functions that handle exactly one row from the source table. We'll have one of these for each target table. In the above example, we've only shown two, you get the idea. Each new source table, with its unique headers can be accommodated.
Can we talk about drama? There is the dark night of the soul for anyone interested in regular, normalized data.
We have some fundamental choices for working with this mess:
- Export each relevant table to separate files. Lots of manual pointy-clicky and opportunities for making mistakes.
- Export the whole thing to separate files. Less pointy-clicky.
- Export the whole thing to one file. About the same pointy-clicky and error vulnerability as #2. But. Simpler still because there's one file to take care of. Something a fiction author should be able to handle.
The prefix is a line with "Sheet: Table" Yes. There's a ": " (colon space) separator. The suffix is a simple blank line, essentially indistinguishable from a blank line within a table.
If the table was originally in strict first normal form (1NF) each row would have the same number of commas. If cells are merged, however, the number of commas can be fewer. This makes it potentially difficult to distinguish blank rows in a table from blank lines between tables.
It's generally easiest to ignore the blank lines entirely. We can distinguish table headers because they're a single cell with a sheet: table format. We are left hoping there aren't any tables that have values that have this format.
We have two ways to walk through the values:
- Preserving the Sheet, Table, Row hierarchy. We can think of this as the for s in sheet: for t in table: for r in rows structure. The sheet iterator is Iterator[Tuple[str, Table_Iterator]]. The Table_Iterator is similar: Iterator[Tuple[str, Row_Iterator]]. The Row_Iterator, is the most granular Iterator[Dict[str, Any]].
- Flattening this into a sequence of "(Sheet name, Table Name, Row)" triples. Since a sheet and table have no other attributes beyond a name, this seems advantageous to me.
The hierarchical form requires a number of generator functions for Sheet-from-CSV, Table-from-CSV, and Row-from-CSV. Each of these works with a single underlying iterator over the source file and a fairly complex hand-off of state. If we only use the sheet iterator, the tables and rows are skipped. If we use the table within a sheet, the first table name comes from the header that started a sheet; the table names come from distinct headers until the sheet name changes.
The table-within-sheet iteration is very tricky. The first table is a simple yield of information gathered by the sheet iterator. Any subsequent tables, however, may be based one one of two conditions: either no rows have been consumed, in which case the table iterator consumes (and ignores) rows; or, all the rows of the table have been consumed and the current row is another "sheet: table" header.
The code sample below involves a fair amount of repetition. It's not appealing to refactor this because it's ungainly in its complexity, and doesn't create any tangible value. (I haven't even tried to get the type hints right.)
class SheetTable:
def __init__(self, source_path: Path) -> None:
self.path: Path = source_path
self.csv_source = None
self.rdr = None
self.header = None
self.row = None
def __enter__(self) -> None:
self.csv_source = self.path.open()
self.rdr = csv.reader(self.csv_source)
self.header = None
self.row = next(self.rdr)
return self
def __exit__(self, *args) -> None:
self.csv_source.close()
def _sheet_header(self) -> bool:
return len(self.row) == 1 and ': ' in self.row[0]
def sheet_iter(self):
while True:
while not (self._sheet_header()):
try:
self.row = next(self.rdr)
except StopIteration:
return
self.sheet, _, self.table = self.row[0].partition(": ")
self.header = next(self.rdr)
self.row = next(self.rdr)
yield self.sheet, self.table_iter()
def table_iter(self):
yield self.table, self.row_iter()
while not (self._sheet_header()):
try:
self.row = next(self.rdr)
except StopIteration:
return
next_sheet, _, next_table = self.row[0].partition(": ")
while next_sheet == self.sheet:
self.table = next_table
self.header = next(self.rdr)
self.row = next(self.rdr)
yield self.table, self.row_iter()
while not (self._sheet_header()):
try:
self.row = next(self.rdr)
except StopIteration:
return
next_sheet, _, next_table = self.row[0].partition(": ")
def row_iter(self):
while not self._sheet_header():
yield dict(zip(self.header, self.row))
try:
self.row = next(self.rdr)
except StopIteration:
return
Flattening is much nicer.
def sheet_table_iter(source_path: Path) -> Iterator[Tuple[str, str, Dict[str, Any]]]:
with source_path.open() as csv_source:
rdr = csv.reader(csv_source)
header = None
for row in rdr:
if len(row) == 0:
continue
elif len(row) == 1 and ": " in row[0]:
sheet, table = row[0].split(": ", maxsplit=1)
header = next(rdr)
continue
else:
# Inject headers to create dict from row
yield sheet, table, dict(zip(header, row))
This provides a relatively simple way to find the relevant tables and sheets. We can use something as simple as the following to locate the relevant data.
for sheet, table, row in sheet_table_iter(source_path):
if sheet == 'AgentQuery' and table == 'agent_query':
agent = agent_query_row(database, row)
elif sheet == 'AAR-2019-03' and table == 'Table 1':
agent = aar_2019_row(database, row)
This lets us write pleasant functions that handle exactly one row from the source table. We'll have one of these for each target table. In the above example, we've only shown two, you get the idea. Each new source table, with its unique headers can be accommodated.
Tuesday, October 8, 2019
Spreadsheet Regrets
I can't emphasize this enough.
Some people, when confronted with a problem, think
“I know, I'll use a spreadsheet.” Now they have two problems.
(This was originally about regular expressions. And AWK. See http://regex.info/blog/2006-09-15/247)
Fiction writer F. L. Stevens got a list of literary agents from AAR Online. This became a spreadsheet driving queries for representation. After a bunch of rejections, another query against AAR Online provided a second list of agents.
Apple's Numbers product will readily translate the AAR Online HTML table into a usable spreadsheet table. But after initial success the spreadsheet as tool of choice collapses into a pile of rubble. The spreadsheet data model is hopelessly ineffective for the problem domain.
What is the problem domain?
There are two user stories:
Some people, when confronted with a problem, think
“I know, I'll use a spreadsheet.” Now they have two problems.
(This was originally about regular expressions. And AWK. See http://regex.info/blog/2006-09-15/247)
Fiction writer F. L. Stevens got a list of literary agents from AAR Online. This became a spreadsheet driving queries for representation. After a bunch of rejections, another query against AAR Online provided a second list of agents.
Apple's Numbers product will readily translate the AAR Online HTML table into a usable spreadsheet table. But after initial success the spreadsheet as tool of choice collapses into a pile of rubble. The spreadsheet data model is hopelessly ineffective for the problem domain.
What is the problem domain?
There are two user stories:
- Author needs to deduplicate agents and agencies. It's considered poor form to badger agents with repeated queries for the same title. It's also bad form to query two agents at the same agency. You have to get rejected by one before contacting the other.
- Author needs to track activities at the Agent and Agency level to optimize querying. This mostly involves sending queries and tracking rejections. Ideally, an agent acceptance should lead to notification to other agents that the manuscript is being withdrawn. This is so rare as to not require much automation.
Agents come and go. Periodically, an agent will be closed to queries for some period of time, and then reopen. Their interests vary with the whims of the marketplace they're trying to serve. Traditional fiction publishing is quite complex; agents are the gatekeepers.
To an extent, we can decompose the processing like this.
1. Sourcing. There are several sources: AAR Online and Agent Query are two big sources. These sites have usable query engines and the HTML can be scraped to get a list of currently active agents with a uniform representation. This is elegant Python and Beautiful Soup.
2. Deduplication. Agency and Agent deduplication is central. Query results may involve state changes to an agent (open to queries, interested in new genres.) Query results may involve simple duplicates, which have to be discarded to avoid repeated queries. It's a huge pain when attempted with a spreadsheet. The simplistic string equality test for name matching is defeated by whitespace variations, for example. This is elegant Python, however.
3. Agent web site checks. These have to be done manually. Agency web pages are often art projects, larded up with javascript that produces elegant rolling animations of books, authors, agents, background art, and text. These sites aren't really set up to help authors. It's impossible to automate a check to confirm the source query results. This has to be done manually: F. L. is required to click and update status.
4. State Changes. Queries and Rejections are the important state changes. Open and Closed to queries is also part of the state that needs to be tracked. Additionally, there's a multiple agent per agency check that makes this more complex. The state changes are painful to track in a simple spreadsheet-like data structure: a rejection by one agent can free up another agent at the same agency. This multi-row state change is simply horrible to deal with.
Bonus confusion! Time-to-Live rules: a query over 60 days old is more-or-less a de facto rejection. This means that periodic scans of the data are required to close a query to one agent in an agency, freeing up subsequent agents in the same agency.
Bonus confusion! Time-to-Live rules: a query over 60 days old is more-or-less a de facto rejection. This means that periodic scans of the data are required to close a query to one agent in an agency, freeing up subsequent agents in the same agency.
Manuscript Wish Lists (MSWLs) are a source for agents actively searching for manuscripts. This is more-or-less a Twitter query. Using the various aggregating web sites seems slightly easier than using Twitter directly. However, additional Twitter lookups are required to locate agent details, so this is interesting web-scraping.
Of course F. L. Stevens has a legacy spreadsheet with at least four "similar" (but not really identical) tabs filled with agencies, agents, and query status.
Of course F. L. Stevens has a legacy spreadsheet with at least four "similar" (but not really identical) tabs filled with agencies, agents, and query status.
I don't have an implementation to share -- yet. I'm working on it slowly.
I think it will be an interesting tutorial in cleaning up semi-structured data.
I think it will be an interesting tutorial in cleaning up semi-structured data.
Tuesday, September 10, 2019
Packt Data Unlocked Promotion
See http://bit.ly/DataUnlockedTwitter
You can't go wrong with these kinds of discounts.
#DataUnlocked
You can't go wrong with these kinds of discounts.
#DataUnlocked
Tuesday, September 3, 2019
Finally Planning the Rewrite of Building Skills in Object-Oriented Design
See Building Skills in Object-Oriented Design for the old content, which has a number of features that hold up well over time.
- A graduated series of exercises to build up large, complete applications is important.
- It covers a lot of skills essential to building real applications -- unit testing, integration, code reuse. I want to expand on this to include more testing strategies, and final documentation.
- It's so popular, I've got enough donations to move forward on a rewrite.
Previously, it was hosted out of my ancient web site as HTML and PDF download. That hasn't aged well.
Also, it was originally Python 2, and that ship sailed years ago.
I'm leaning toward hosting the content on GitHub.
One idea is to have a complex project with the following top-level folders:
- A docs folder that has the HTML as well as PDF (and maybe an ebook format, too.)
- A src folder with seed files for the various packages and modules.
- A tests folder with seed tests.
Someone could fork and then build on the framework.
It's possible to put the exposition into the wiki pages associated with the repo. This has the advantage of keeping the meta-level documentation and individual project requirements separate from the project itself.
Before I go too far, I'll need to experiment a bit to see what the editing process is like. The Github wiki pages are their own git branch, and are easy to edit off-line and push to the repo. Some of the fancy Sphinx markup features vanish, replaced with basic RST. This may not be all bad, since the baseline content is not *very* complex.
Stand by for more.
Tuesday, August 13, 2019
Coping with Windows via AWS
For a training class, I needed to address The Windows Problem™. TWP is the my summary of all the non-standard features of Windows in its various inconsistent incarnations.
Any training class that involves "install Python" inevitably involves at least one Windows user who can't get their PATH set correctly. It's an eternal mystery to me, since the installers all seem to take care of this, but, some people are able to click the wrong thing somewhere in a simple installation.
The uninstall and start again sometimes helps. Having a Windows expert in the room sometimes helps.
(The hapless flailing I sometimes observe is my personal problem to deal with. I should not let myself get short-tempered with people who try things exactly once and then stop, unable to discern a single branch in the path they chose. It's as if the sequence of dialog boxes with different choices never existed for them, and I need to respect the fact that they did not read the messages and did not think of themselves as actively making choices.)
I have to say that being able to get a Windows machine in free tier of AWS is a wonderful resource.
I can screen capture the installation on Windows.
I can narrate the sequence of choices I made. I'm hoping this prevents TWP from side-tracking a person who's struggling with Windows.
I haven't used the movies yet. But it's so handy to be able to spin up a Windows machine in the cloud and run the Conda install. It's a whole lot nicer than buying a throw-away Windows machine to do screen shots on.
Any training class that involves "install Python" inevitably involves at least one Windows user who can't get their PATH set correctly. It's an eternal mystery to me, since the installers all seem to take care of this, but, some people are able to click the wrong thing somewhere in a simple installation.
The uninstall and start again sometimes helps. Having a Windows expert in the room sometimes helps.
(The hapless flailing I sometimes observe is my personal problem to deal with. I should not let myself get short-tempered with people who try things exactly once and then stop, unable to discern a single branch in the path they chose. It's as if the sequence of dialog boxes with different choices never existed for them, and I need to respect the fact that they did not read the messages and did not think of themselves as actively making choices.)
I have to say that being able to get a Windows machine in free tier of AWS is a wonderful resource.
I can screen capture the installation on Windows.
I can narrate the sequence of choices I made. I'm hoping this prevents TWP from side-tracking a person who's struggling with Windows.
I haven't used the movies yet. But it's so handy to be able to spin up a Windows machine in the cloud and run the Conda install. It's a whole lot nicer than buying a throw-away Windows machine to do screen shots on.
Friday, July 5, 2019
Mastering Object-Oriented Python 2nd ed
The book https://www.packtpub.com/programming/mastering-object-oriented-python-second-edition
Some new chapters.
Type hints almost everywhere.
If you want to write a review, DM me on twitter @s_lott I can add you to the list for freebies in exchange for a review.
Thursday, June 20, 2019
HumbleBundle -- Functional Python Programming -- Through July 1
See this https://www.humblebundle.com
This is amazing to me.
Humble Bundle sells games, ebooks, software, and other digital content. Our mission is to support charity while providing awesome content to customers at great prices. We launched in 2010 with a single two-week Humble Indie Bundle, but we have humbly grown into a store full of games and bundles, a subscription service, a game publisher, and more.
Currently, Packt is offering some of my books.
Want a *ton* of technical books and donate to charity?
Click Now. Thank me later.
Tuesday, June 18, 2019
The Pythonista app for iPad
Let me start my review with "wow!"
Python 3.6 on the iPad. Works. Nicely. Easy to use. Reliable. Rock-Solid.
I'm not switching to iPad as my primary platform any time in the near future. But. For certain kinds of small and tightly focused hackery, this is really nice.
I use a bracket to hold the iPad up and an external keyboard. I can be used with the on-screen keyboard, but, that's slow-going for me.
Here's the thing that was exquisitely simple in Pythonista:
Python 3.6 on the iPad. Works. Nicely. Easy to use. Reliable. Rock-Solid.
I'm not switching to iPad as my primary platform any time in the near future. But. For certain kinds of small and tightly focused hackery, this is really nice.
I use a bracket to hold the iPad up and an external keyboard. I can be used with the on-screen keyboard, but, that's slow-going for me.
Here's the thing that was exquisitely simple in Pythonista:

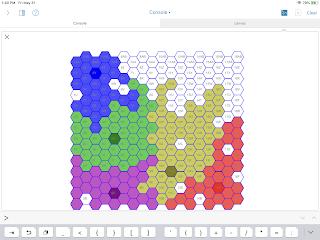
I'm able to draw a hex grid ("Flat Top", "Double Height") in a few dozen lines of code. This includes a bunch of geometry rules like adjacency and directional movement.
The Pythonista package includes a super-easy-to-use
Given a HexGrid instance, I can then create "cities" and their surrounding territories in an "empire". I've tried a few organic growth algorithms, and I like the look of these maps. They provide a lot of avenues for conflict for writing fiction or playing role-playing games.
Some of the algorithmic foundations: https://www.redblobgames.com/grids/hexagons/.
It's pretty slow. No surprise there. It's running on an iPad.
It's pretty easy to work on. Whip out the iPad and start coding.
The super-easy, built-in
I can see having an intro to programming class where the fee includes an extra $800 for the iPad you take home along with your new-found skills in basic coding. (This is still a *lot* of money, but it's less than a full laptop.)
However, there are still some "Edge" cases that are challenging.
Location 12D reflects a hole on a border. These are interesting, and could be the seed for epic wargaming, role-playing game, novel-writing drama. A simple algorithm can find these and assign a random owner... But... They really need a special "On Fire" color scheme to show the potential for drama.
There's a subtlety in the upper-left corner (5W and 6V) between Blue and Green. While these seem like simple border holes, each hole as only five of six required neighbors.
Compare these with 16P in the upper-right corner. This also has five of six neighbors. However, this space looks like it could be a bay leading up to a river and the river is a natural border between nations.
The head of the bay at 16P has 5 neighbors of two colors, similar to 5W and 6V. The difference can be detected by a recursive walk to see if a hole is connected to other holes and the composite is actually surrounded. There are lots of *edge* cases, but the (5W, 6V) pair seems to embody the next stage of surround detection.
This more nuanced algorithm design doesn't work out well in the Pythonista environment. This algorithm design requires careful unit tests, not the code-and-run cycle of hackery. For this kind of careful design, we'd need to leverage
If you're an iPad user, consider adding Pythonista. You can really write real Python. It's a useful environment. It's fun for teaching.
The Pythonista package includes a super-easy-to-use
canvas module that's a tiny bit simpler than turtle graphics. It takes a bit of getting used to, but it has enough graphics primitives to make it easy to create hexagons and tile the surface.Given a HexGrid instance, I can then create "cities" and their surrounding territories in an "empire". I've tried a few organic growth algorithms, and I like the look of these maps. They provide a lot of avenues for conflict for writing fiction or playing role-playing games.
Some of the algorithmic foundations: https://www.redblobgames.com/grids/hexagons/.
Fun Hackery
This is fun hackery because I can change the code, click the run icon, and watch the consequence of the changes. A traceback is highlighted in the original file. Easy. Fun.It's pretty slow. No surprise there. It's running on an iPad.
It's pretty easy to work on. Whip out the iPad and start coding.
The super-easy, built-in
canvas module means feedback is instant and gratifying.I can see having an intro to programming class where the fee includes an extra $800 for the iPad you take home along with your new-found skills in basic coding. (This is still a *lot* of money, but it's less than a full laptop.)
Filling in the Holes
Looking at the output, you can see the growth algorithm left some unfilled holes. A later version examines all unfilled spaces to see if they're entirely surrounded by one color and fills them. This is a fun algorithm because it works in a simple way with the adjacency iterator and the set of locations covered by a city. Locations 12L and 17K are these "Simply Surrounded Single Holes."However, there are still some "Edge" cases that are challenging.
Location 12D reflects a hole on a border. These are interesting, and could be the seed for epic wargaming, role-playing game, novel-writing drama. A simple algorithm can find these and assign a random owner... But... They really need a special "On Fire" color scheme to show the potential for drama.
There's a subtlety in the upper-left corner (5W and 6V) between Blue and Green. While these seem like simple border holes, each hole as only five of six required neighbors.
Compare these with 16P in the upper-right corner. This also has five of six neighbors. However, this space looks like it could be a bay leading up to a river and the river is a natural border between nations.
The head of the bay at 16P has 5 neighbors of two colors, similar to 5W and 6V. The difference can be detected by a recursive walk to see if a hole is connected to other holes and the composite is actually surrounded. There are lots of *edge* cases, but the (5W, 6V) pair seems to embody the next stage of surround detection.
This more nuanced algorithm design doesn't work out well in the Pythonista environment. This algorithm design requires careful unit tests, not the code-and-run cycle of hackery. For this kind of careful design, we'd need to leverage
doctest (or unittest) for testing. While I'd like pytest, that's a lot to ask for. For these kinds of apps, doctest is more than adequate, and a simple import doctest; doctest.testmod() in a scrip can help be sure things work as expected.tl;dr
If you're an iPad user, consider adding Pythonista. You can really write real Python. It's a useful environment. It's fun for teaching.
Tuesday, June 11, 2019
Circuit Python on the Gemma M0 -- The Red Ranger Beacon
PyCon 2018 Swag included a Gemma m0. (https://www.adafruit.com/product/3501)
PyCon 2019 Swag included a Circuit Playground Express. See https://learn.adafruit.com/adafruit-circuit-playground-express/circuitpython-quickstart.
Both of these are (to me) amazing. They mount as USB devices; there’s a code.py file that’s automatically run when the board restarts.
The Gemma has fairly few pins and does some real simple things. The CPX has a bunch of pins and ton of hardware on the board. Buttons, Switches, LED’s, motion sensor, temperature, brightness... I’ve lost count.
Few things are more frustrating than making a mistake and being unable to restore the original functionality as a check to be sure things are still working.
Also. At some point, you'll want to upgrade the OS on the chip. This will require you to have a bootable image. The process isn't complex, but it does require some care. See https://learn.adafruit.com/welcome-to-circuitpython/installing-circuitpython#download-the-latest-version-3-4 for downloading a new OS.
So. Step 1a. Create a local folder for your projects. Within that folder, create a folder for each project. Put the relevant code.py into the sub-folder. Like this
PyCon 2019 Swag included a Circuit Playground Express. See https://learn.adafruit.com/adafruit-circuit-playground-express/circuitpython-quickstart.
Both of these are (to me) amazing. They mount as USB devices; there’s a code.py file that’s automatically run when the board restarts.
The Gemma has fairly few pins and does some real simple things. The CPX has a bunch of pins and ton of hardware on the board. Buttons, Switches, LED’s, motion sensor, temperature, brightness... I’ve lost count.
Step 1 -- Get Organized
Create a proper project directory on your local machine. Yes, you can hack thecode.py file immediately, but you should consider making a backup before you start making changes.Few things are more frustrating than making a mistake and being unable to restore the original functionality as a check to be sure things are still working.
Also. At some point, you'll want to upgrade the OS on the chip. This will require you to have a bootable image. The process isn't complex, but it does require some care. See https://learn.adafruit.com/welcome-to-circuitpython/installing-circuitpython#download-the-latest-version-3-4 for downloading a new OS.
So. Step 1a. Create a local folder for your projects. Within that folder, create a folder for each project. Put the relevant code.py into the sub-folder. Like this
gemma ┣━━ baseline ┃ ┗━━ code.py ┣━━ my-first-project ┃ ┗━━ code.py ┣━━ another-project ┃ ┗━━ code.py ┗━━ os-upgrade ┗━━ other files...
See https://learn.adafruit.com/adafruit-gemma-m0/troubleshooting for additional help if you have a Windows PC.
A lot of folks like the Mu editor for this. https://codewith.mu.
I like using BBEdit. https://www.barebones.com/products/bbedit/. To make this work I *also* need to have
This is a lot of busy screen real-estate with three separate apps open. It's not for everyone. I like it because there's little hand-holding. You may prefer Mu.
It's important to go through the edit/download/play cycle many times to be sure you're clear on what code's on your PC and what code's on your board.
It's even more important to see how you're forced to debug syntax errors using the screen app until you invent a suitable mock library for off-line unit testing.
However.
It's also a very small processor, with very few pins, so you can't do anything super elaborate. You can, however, do quite a bit.
See Nina Zakharenko - Keynote - PyCon 2019 for some inspiration
Many thanks to @nnja for showing us some elegant, inspirational ideas.
Step 2 -- Start Small
Tweak a few things in the suppliedcode.py if you're new to IoT stuff.A lot of folks like the Mu editor for this. https://codewith.mu.
I like using BBEdit. https://www.barebones.com/products/bbedit/. To make this work I *also* need to have
- a terminal window open so I can use the Mac OS screen application, and
- a finder window open to copy the code.py from my PC to the Gemma M0.
This is a lot of busy screen real-estate with three separate apps open. It's not for everyone. I like it because there's little hand-holding. You may prefer Mu.
It's important to go through the edit/download/play cycle many times to be sure you're clear on what code's on your PC and what code's on your board.
It's even more important to see how you're forced to debug syntax errors using the screen app until you invent a suitable mock library for off-line unit testing.
Step 3 -- Plan Carefully
The version of Python is remarkably complete.However.
It's also a very small processor, with very few pins, so you can't do anything super elaborate. You can, however, do quite a bit.
See Nina Zakharenko - Keynote - PyCon 2019 for some inspiration
Step 4 -- Check This Out
https://github.com/slott56/gemma-boat-beaconMany thanks to @nnja for showing us some elegant, inspirational ideas.
Tuesday, June 4, 2019
Probabilistic Data Structures
Interesting data structures with O(n) performance. This can help to unscramble O(n²) problems allowing progress.
https://pdsa.readthedocs.io/en/latest/index.html
https://pdsa.readthedocs.io/en/latest/index.html
Tuesday, May 28, 2019
Rules for Debugging
Here's the situation.
Someone wrote code. It didn't do what they assumed it would do.
They come to me for help.
Here are my rules for debugging. All of them.
1. Try something else.
I don't have any other or more clever advice. When I look at someone's broken code, I'm going to suggest the only thing I know. Try something else.
I can't magically make broken code work. Code's not like that. If it doesn't work, it's wrong, usually in a foundational way. Usually, the author made an assumption, followed through on that assumption, and was astonished it didn't work.
A consequence of this will be massive changes to the broken code. Foundational changes.
Debugging is a matter of finding and discarding assumptions. This can be hard. Some people think their assumptions are solid gold and write long angry blog posts about how a language or platform or library is "broken."
The rest of us try something different.
My personal technique is to cite evidence for everything I think I'm observing. Sometimes, I actually write it down -- on paper -- next to the computer. (Sometimes I use the Mac OS Notes app.) Which lines of code. Which library links. Sometimes, i'll include in the code as references to documentation pages.
Evidence is required to destroy assumptions. Destroying assumptions is the essence of debugging.
I'm often amazed that someone can try to use multiprocessing.apply_async() without reading any of the example code. What I'm guessing is that assumptions trump research, making them solid gold, and not subject to questioning or locating evidence. In the case of multiprocessing, it's important to look at code which appears broken and compare it, line-by-line with example code that works.
Comparing broken code with relevant examples is -- in effect -- trying something else. The original didn't work. So... Go to something that does work and compare the two to identify the differences.
Someone wrote code. It didn't do what they assumed it would do.
They come to me for help.
Here are my rules for debugging. All of them.
1. Try something else.
I don't have any other or more clever advice. When I look at someone's broken code, I'm going to suggest the only thing I know. Try something else.
I can't magically make broken code work. Code's not like that. If it doesn't work, it's wrong, usually in a foundational way. Usually, the author made an assumption, followed through on that assumption, and was astonished it didn't work.
A consequence of this will be massive changes to the broken code. Foundational changes.
When you make an assumption, you make an "ass" out of "u" and "mption".
Debugging is a matter of finding and discarding assumptions. This can be hard. Some people think their assumptions are solid gold and write long angry blog posts about how a language or platform or library is "broken."
The rest of us try something different.
My personal technique is to cite evidence for everything I think I'm observing. Sometimes, I actually write it down -- on paper -- next to the computer. (Sometimes I use the Mac OS Notes app.) Which lines of code. Which library links. Sometimes, i'll include in the code as references to documentation pages.
Evidence is required to destroy assumptions. Destroying assumptions is the essence of debugging.
Sources of Assumptions
I'm often amazed at how many people don't read the "But on Windows..." parts of the Python documentation. Somehow, they're willing to assume -- without evidence -- that Windows is POSIX-compliant and behaves like Linux. When things don't follow their assumed behavior, and they're using Windows, it often seems like they've compounded a bunch of personal assumptions. I don't have too much patience at this point: the debugging is going to be hard.I'm often amazed that someone can try to use multiprocessing.apply_async() without reading any of the example code. What I'm guessing is that assumptions trump research, making them solid gold, and not subject to questioning or locating evidence. In the case of multiprocessing, it's important to look at code which appears broken and compare it, line-by-line with example code that works.
Comparing broken code with relevant examples is -- in effect -- trying something else. The original didn't work. So... Go to something that does work and compare the two to identify the differences.
Tuesday, May 21, 2019
Tuesday, May 14, 2019
PyCon 2019
There are some things I could say.
But.
You can come to understand it yourself, also.
Go here: https://www.youtube.com/channel/UCxs2IIVXaEHHA4BtTiWZ2mQ
Start with the keynotes. https://www.youtube.com/channel/UCxs2IIVXaEHHA4BtTiWZ2mQ/search?query=keynote
For me, one of the top presentations was this https://www.youtube.com/watch?v=9G2s1TN9QQY
There are several closely related, but I found this very helpful.
But.
You can come to understand it yourself, also.
Go here: https://www.youtube.com/channel/UCxs2IIVXaEHHA4BtTiWZ2mQ
Start with the keynotes. https://www.youtube.com/channel/UCxs2IIVXaEHHA4BtTiWZ2mQ/search?query=keynote
For me, one of the top presentations was this https://www.youtube.com/watch?v=9G2s1TN9QQY
There are several closely related, but I found this very helpful.
Tuesday, May 7, 2019
Fiction Writers and Query Letters
See http://flstevens.itmaybeahack.com/writing-world-building-and/ for some back-story on F. L. Stevens and the need to write a *lot* of query letters to agents for fiction. (The non-fiction industry is entirely different; there are acquisition editors who look for technical contributors.)
There's a tiny possibility of a Query Manager Tool (of some kind) on a writer's desktop.
Inputs include:
There's a tiny possibility of a Query Manager Tool (of some kind) on a writer's desktop.
Inputs include:
- Template letter.
- A table of customizations per Agent. The intent is to allow more than simple name and pronoun changes. This includes Agent-specific content requirements. These vary, and can include the synopsis, first chapter, first 10 pages, first 50 pages. They're not email attachments; they have to be part of the main body of the email, so they're easy to prepare.
- Another table of variant pitches to plug into the template. There are a lot of common variations on this theme. Sizes vary from as few as 50 words to almost 300 words. Summaries of published works seem to have a median size of 140 words. A writer may have several (or several dozen) variants to try out.
This can't become a spam engine (agents don't like the idea of an impersonal letter.)
Also. A stateful list of agents, queries, and responses is important. Some Agents don't necessarily respond to each query; they often offer a blanket apology along the lines of "if you haven't heard back in sixty days, consider it a rejection." So. You want to try again. Eventually. Without being rude. And if you requery, you have to send a different variant on the basic pitch.
Some Agents give a crisp "nope" and you can update your list to avoid requerying.
For new authors (like F. L. Stevens,) there's a kind of manual query tracking mess. It's not really horrible. But it is annoying. Keeping the database up-to-date with responses is about as hard as a tracking spreadsheet, so, there's little value to a lot of fancy Python software.
The csv, string.Temple, email and smtplib components of Python make this really easy to do. While I think it would be fun to write, creating this would be work avoidance.
Tuesday, April 9, 2019
PyLit-3 Maintenance, Love and Care
The PyLit tool dates from 2009. Here's a historical reference: http://wiki.c2.com/?PyLit
It was Python 2. It had some minor problems. I forked it and cleaned it up for Python 3.
Then I set it aside for a few years (six or so.)
Dusting it off. Rearranging things. The legacy Python 2 version -- it appears -- is gone forever.
The current thing available in PyPI doesn't even download and install on a modern Python because the metadata makes it look like it won't be compatible with a Python 3.7 world. So. That needs to be fixed. And while I'm at it...
- Add tox support for Python 3.5, 3.6, and 3.7 properly.
- Restructure the docs to use Github Pages from master/docs.
- Get the download squared away so pip install will work.
- Use pathlib.
- Start down the road toward type hinting. Which will likely exclude py35 support.
I may, as part of type hinting, be forced to make some more changes to the essential structure of the app(s).
For now, I simply need to get it to be pip installable.
It was Python 2. It had some minor problems. I forked it and cleaned it up for Python 3.
Then I set it aside for a few years (six or so.)
Dusting it off. Rearranging things. The legacy Python 2 version -- it appears -- is gone forever.
The current thing available in PyPI doesn't even download and install on a modern Python because the metadata makes it look like it won't be compatible with a Python 3.7 world. So. That needs to be fixed. And while I'm at it...
- Add tox support for Python 3.5, 3.6, and 3.7 properly.
- Restructure the docs to use Github Pages from master/docs.
- Get the download squared away so pip install will work.
- Use pathlib.
- Start down the road toward type hinting. Which will likely exclude py35 support.
I may, as part of type hinting, be forced to make some more changes to the essential structure of the app(s).
For now, I simply need to get it to be pip installable.
Tuesday, March 26, 2019
Python and pathlib and Windows -- this problem has been solved -- and yet...
The Passive-Aggressive Programmer strikes again. A sad story of sadness.
I tell everyone to stop using os.path and use pathlib. Everyone. Here's the link: https://docs.python.org/3/library/pathlib.html
It's essential to realize the semantic richness of OS filesystem paths. They're not simply strings. They have a string representation, but there's quite a bit going on there that is not captured trivially by strings and string parsing. "path/basename.extension" is more than just slashes and dots.
Windows users, of course, have a nightmarish problem. Actually many nightmarish problems, one of which is pathnames.
I tell Windows developers to use pathlib, it will make their life somewhat more bearable.
And Yet. The Passive-Aggressive Programmer insists on using Windows as if it doesn't have a problem with \ in path strings.
Line 110 has a literal r"C:\windows\is\xtreme\evil" Note the \x in the path. Without the r"" string, this literal raises a SyntaxError.
Line 50 had subprocess.run(r"C:\path\to\xectuable -option" + " " + options + " " + filename). Note the r"" string. Note the Linux-style -option, too. They're wrapping an open source app in a Python shell.
You're with me so far? They're Windows devs. They've managed to use raw strings in two places. Right?
But. They're Passive-Aggressive. They don't like PR comments of any kind. They'll "agree" to a change, but then... This...
Line 50 should change. It's needs to use a list.
The Passive Aggressive Programmer can't make a list work.
See what they did there? They didn't want to change from string to list. (We had to go over it more than once.) They wanted to leave it alone. Grudgingly, they agreed to change from string to list.
But.
SyntaxError. See? The list just doesn't work. Python is weird. It's an undocumented WAT.
[Yes, some of us know the r's vanished. They author couldn't figure that out, though.]
And the pathlib suggestion?
Since the strings are now a SyntaxError, they need me to fix that for them. I made them change to a list, therefore, I caused the SyntaxError. It would be a distraction to spend tome researching pathlib. "I need to Google and think about how to handle the Unicode error" was the response.
Using Path("C:/path/to/xecutable") to avoid any Window-ism of any kind is an impossible burden. Impossible. It requires them to Google. Instead, the SyntxError is all my fault.
The previous examples of the use of raw strings? Don't know why they're not helpful, but I'm not the one who's struggling to implement a change.
I tell everyone to stop using os.path and use pathlib. Everyone. Here's the link: https://docs.python.org/3/library/pathlib.html
It's essential to realize the semantic richness of OS filesystem paths. They're not simply strings. They have a string representation, but there's quite a bit going on there that is not captured trivially by strings and string parsing. "path/basename.extension" is more than just slashes and dots.
Windows users, of course, have a nightmarish problem. Actually many nightmarish problems, one of which is pathnames.
I tell Windows developers to use pathlib, it will make their life somewhat more bearable.
And Yet. The Passive-Aggressive Programmer insists on using Windows as if it doesn't have a problem with \ in path strings.
Line 110 has a literal r"C:\windows\is\xtreme\evil" Note the \x in the path. Without the r"" string, this literal raises a SyntaxError.
Line 50 had subprocess.run(r"C:\path\to\xectuable -option" + " " + options + " " + filename). Note the r"" string. Note the Linux-style -option, too. They're wrapping an open source app in a Python shell.
You're with me so far? They're Windows devs. They've managed to use raw strings in two places. Right?
But. They're Passive-Aggressive. They don't like PR comments of any kind. They'll "agree" to a change, but then... This...
Line 50 should change. It's needs to use a list.
The Passive Aggressive Programmer can't make a list work.
list_of_arguments = ["C:\path\to\xectuable -option"] + options_list + ["C:\windows\is\xtreme\evil"]
See what they did there? They didn't want to change from string to list. (We had to go over it more than once.) They wanted to leave it alone. Grudgingly, they agreed to change from string to list.
But.
SyntaxError. See? The list just doesn't work. Python is weird. It's an undocumented WAT.
[Yes, some of us know the r's vanished. They author couldn't figure that out, though.]
And the pathlib suggestion?
Since the strings are now a SyntaxError, they need me to fix that for them. I made them change to a list, therefore, I caused the SyntaxError. It would be a distraction to spend tome researching pathlib. "I need to Google and think about how to handle the Unicode error" was the response.
Using Path("C:/path/to/xecutable") to avoid any Window-ism of any kind is an impossible burden. Impossible. It requires them to Google. Instead, the SyntxError is all my fault.
The previous examples of the use of raw strings? Don't know why they're not helpful, but I'm not the one who's struggling to implement a change.
Tuesday, March 19, 2019
Don't Solve My Problem.
Two and a half examples of "Don't solve the problem I described. Provide the implementation I dream about."
The accepted answer links to some useful design principles. Read the answer. It's useful.
The question objects to abstract superclasses without much (or any) actual implementation. I've seen folks toy around with frameworks where there are classes that introduce a name, but little else. So I understand the complaint. I once tried to use Python classes as surrogates for Java interfaces. It was a bad idea. And irrelevant to solving the underlying problem.
The problem that lead to the "yet another abstraction" complaint, however, was not related to a design with empty layers of framework abstractions. It was not related to classes used to define an interface-like feature in Python. It wasn't related to *anything* in the Stack Overflow question or answer.
The "yet another abstraction" complaint was based on Python not having constants. Seriously. How did we get here? Right. They don't want a solution. They want to complain.
I lift this situation up to folks who are trapped in conversations where things devolve into bizarro-world like "Yet Another Abstraction is bad" when we're not talking about abstractions. The solution is simple, but, it's not what they wanted so, it's labeled as bad in some way.
The solution is bad because it's unexpected. Consequently peripheral, tangential, weird-ass nonsense will show up in trying to avoid an unexpected solution.
We're good here. The data structure's key can be (name, number) and the default number is zero. Works for almost everyone.
Almost everyone. Exception they have one client who cannot count or enumerate their data.
Really.
The client can't even pre-process the data to add numbers because reasons.
The stated reason is "the data originates off-line and the numbers might be inconsistent." The key needs a number. It doesn't need to consistent. The point is asking the client to own the identity -- a name and a number.
The solution seemed easy. Assign a number. If your data comes from a spread-sheet, use the row number. The =row() function works. Use that. If your data doesn't come from a spread-sheet write a tiny utility to laminate a number into the data. This doesn't seem hard. And then the client owns the object identity.
Nope.
Can't do it. The web service will have to assign the number for them.
It's not a difficult feature to add. It's a complicated, stateful default value. This will turn into trouble tickets in the future when the numbers are unacceptable because they change with each load or something even more obscure than that.
There are people who have a vision: How Things Should Be (HTSB™,) They seem to be utterly unwilling to consider something that is not literally their (narrow) vision of HTSB.
It's very much as "Don't confuse me with facts, my mind is made up" situation. It's exasperating to me because of the irrelevant side-channel discussions they use to avoid confronting (or even stating) the actual problem.
Can't Use Enums for Constants
I was asked to see this because sometimes there's just too much abstraction https://stackoverflow.com/questions/2668355/how-much-abstraction-is-too-muchThe accepted answer links to some useful design principles. Read the answer. It's useful.
The question objects to abstract superclasses without much (or any) actual implementation. I've seen folks toy around with frameworks where there are classes that introduce a name, but little else. So I understand the complaint. I once tried to use Python classes as surrogates for Java interfaces. It was a bad idea. And irrelevant to solving the underlying problem.
The problem that lead to the "yet another abstraction" complaint, however, was not related to a design with empty layers of framework abstractions. It was not related to classes used to define an interface-like feature in Python. It wasn't related to *anything* in the Stack Overflow question or answer.
The "yet another abstraction" complaint was based on Python not having constants. Seriously. How did we get here? Right. They don't want a solution. They want to complain.
I lift this situation up to folks who are trapped in conversations where things devolve into bizarro-world like "Yet Another Abstraction is bad" when we're not talking about abstractions. The solution is simple, but, it's not what they wanted so, it's labeled as bad in some way.
The solution is bad because it's unexpected. Consequently peripheral, tangential, weird-ass nonsense will show up in trying to avoid an unexpected solution.
Can't Assign Numbers
There's an API to load some data. They have 100's of clients happily loading data. In some cases, the clients must assign numbers in addition to names; it's a disambiguation thing. Most of the time, the name is good. In a few cases, (name, number) is a two-part key because they have multiple instances with the same name.We're good here. The data structure's key can be (name, number) and the default number is zero. Works for almost everyone.
Almost everyone. Exception they have one client who cannot count or enumerate their data.
Really.
The client can't even pre-process the data to add numbers because reasons.
The stated reason is "the data originates off-line and the numbers might be inconsistent." The key needs a number. It doesn't need to consistent. The point is asking the client to own the identity -- a name and a number.
The solution seemed easy. Assign a number. If your data comes from a spread-sheet, use the row number. The =row() function works. Use that. If your data doesn't come from a spread-sheet write a tiny utility to laminate a number into the data. This doesn't seem hard. And then the client owns the object identity.
Nope.
Can't do it. The web service will have to assign the number for them.
It's not a difficult feature to add. It's a complicated, stateful default value. This will turn into trouble tickets in the future when the numbers are unacceptable because they change with each load or something even more obscure than that.
Can't Fork a Repo
This isn't recent, and I may not have the details right. But.
The team had evolved an approach where they had several different pieces of software spread among multiple branches in a single Git repository.
This was weird. And they were -- of course -- about to start having CI/CD problems as they moved away from manual builds into a world of git commit hooks and relatively fixed CI/CD pipelines.
And they were really unhappy. They liked having multiple branches in a single repo. The idea of forking this into separate repos was unacceptable. Unworkable. Breaks everything. (Breaks everything they had. Everything they needed to replace. Or so they claimed.)
They had some vision of having the CI/CD jobs all reworked to move beyond the common dev/master world into their uniquely odd world of lots of parallel branches, each it's own private "master". But all in one repo.
They seemed to have locked into a strange world view, and weren't happy discarding it. The circular discussions of how multiple repos would break something something in their something was more examples of tangential, irrelevant discussion to cloak empty whining.
tl;dr
I think there are people who don't really want a "solution." They want something else.There are people who have a vision: How Things Should Be (HTSB™,) They seem to be utterly unwilling to consider something that is not literally their (narrow) vision of HTSB.
It's very much as "Don't confuse me with facts, my mind is made up" situation. It's exasperating to me because of the irrelevant side-channel discussions they use to avoid confronting (or even stating) the actual problem.
Tuesday, March 12, 2019
Python's multi-threading and the GIL
Got this in an email.
Sigh.
No question on "What was recommended?" or "What's a common solution?" or "What is Dask?" Nothing other than "confirm my assumptions."
This is swirling around a bunch of emails on trying to determine the maximum number of concurrent threads or processes based on the number of cores or CPU's or something.
Maximum.
I'll repeat that for those who skim.
They think there's a maximum number of concurrent threads or processes.
If you have some computation which (1) makes zero OS requests and (2) is never interrupted, I can imagine you'd like to have all of the cores fully committed to executing that theoretical stream of instructions. You might even be able to split that theoretical workload up based on the number of cores.
Practically, however, that stream of uninterrupted computing rarely exists.
Maybe. Maybe you've got some basin-hopping or gradient-following or random forest ML algorithm which is going to do a burst of computation on an in-memory data structure. In that (rare) case, Dask is still ideal for exploiting all of the cores on your processor.
The upper-bound idea bugs me a lot.
What's the maximum number of threads or processes? It depends on the wait times. It depends on memory writes. It depends on the size of the data structure, the size of cache, and the size of the instruction stream.
Because it depends on a lot of things, it's rather difficult to predict. And that makes it rather difficult to determine a maximum.
Replying about the uselessness of trying to establish a maximum, of course, does nothing. AFAIK, they're still assiduously trying to use os.cpu_count() and os.sched_getaffinity() to put an upper bound on the size of a thread pool.
Acting as if Dask doesn't exist.
Or
Use a multiprocessing pool.
These are simple things. They don't require a lot of hand-wringing over the GIL and Thread Local Data. They're built. They work. They're simple and effective solutions.
Indeed. Asking for my confirmation of using Thread-Local Data to avoid the GIL is -- effectively -- yet another Appeal to Authority. Don't ask me if you have a good idea. An appeal to me as an authority is exactly as bad as appeal to some other authority to convince me you've found a corner case that no one has ever seen before.
Worse is to ask me and then blah-blah-blah Steve Lott says blah-blah-blah. Please don't.
I can be (and often am) wrong.
Write your code. Measure your code's performance. Tell me your results. Explore *all* the alternatives while you're at it.
"Python's multi-threading module seems not efficient because of the global interpreter lock?"Yep.
Nope.Is the trick is to use "Thread-Local Data"?
It Gets Worse
Interestingly, there was no further ask. The questioner had decided on thread-local data because the questioner had decided to focus on threads. And they were done making choices at that point.Sigh.
No question on "What was recommended?" or "What's a common solution?" or "What is Dask?" Nothing other than "confirm my assumptions."
This is swirling around a bunch of emails on trying to determine the maximum number of concurrent threads or processes based on the number of cores or CPU's or something.
Maximum.
I'll repeat that for those who skim.
They think there's a maximum number of concurrent threads or processes.
If you have some computation which (1) makes zero OS requests and (2) is never interrupted, I can imagine you'd like to have all of the cores fully committed to executing that theoretical stream of instructions. You might even be able to split that theoretical workload up based on the number of cores.
Practically, however, that stream of uninterrupted computing rarely exists.
Maybe. Maybe you've got some basin-hopping or gradient-following or random forest ML algorithm which is going to do a burst of computation on an in-memory data structure. In that (rare) case, Dask is still ideal for exploiting all of the cores on your processor.
The upper-bound idea bugs me a lot.
- Any OS request leads to a context switch. Any context switch leads to waiting. Any waiting means you can have more threads than you have cores.
- AFAIK, any memory write outside the local cache will lead to a stall in the pipeline. Another thread can (and should) leap in to the core's processing stream. The only way you can create the "all-computing" sequence of instructions bounded by the number of cores is to *also* be sure the entire thing fits in cache. Hahahaha.
What's the maximum number of threads or processes? It depends on the wait times. It depends on memory writes. It depends on the size of the data structure, the size of cache, and the size of the instruction stream.
Because it depends on a lot of things, it's rather difficult to predict. And that makes it rather difficult to determine a maximum.
Replying about the uselessness of trying to establish a maximum, of course, does nothing. AFAIK, they're still assiduously trying to use os.cpu_count() and os.sched_getaffinity() to put an upper bound on the size of a thread pool.
Acting as if Dask doesn't exist.
Solution
Use Dask.Or
Use a multiprocessing pool.
These are simple things. They don't require a lot of hand-wringing over the GIL and Thread Local Data. They're built. They work. They're simple and effective solutions.
Side-bar Nonsense
From "a really smart guy. He got his PhD in quantum mechanics and he got major money to actually go build … . He initially worked for ... and now he is working for .... So, when he says something or asks a question, I listen very carefully."The laudatory blah-blah-blah doesn't really change the argument. It can be omitted. It is an "Appeal to Authority" fallacy, and the Highest Paid Person's Opinion (HIPPO) organizational pattern. Spare me.
Indeed. Asking for my confirmation of using Thread-Local Data to avoid the GIL is -- effectively -- yet another Appeal to Authority. Don't ask me if you have a good idea. An appeal to me as an authority is exactly as bad as appeal to some other authority to convince me you've found a corner case that no one has ever seen before.
Worse is to ask me and then blah-blah-blah Steve Lott says blah-blah-blah. Please don't.
I can be (and often am) wrong.
Write your code. Measure your code's performance. Tell me your results. Explore *all* the alternatives while you're at it.
Tuesday, March 5, 2019
Python exceptions considered an anti-pattern
https://sobolevn.me/2019/02/python-exceptions-considered-an-antipattern
While eloquent and thorough, I remain unconvinced that this is a significant improvement over try/except.
It's common enough in some functional languages to have strong support and a long, successful history.
I think it replaces one problem with another. It's not a "solution". It's an alternative. Instead of exceptions being raised, they're returned. Cool.
While eloquent and thorough, I remain unconvinced that this is a significant improvement over try/except.
It's common enough in some functional languages to have strong support and a long, successful history.
I think it replaces one problem with another. It's not a "solution". It's an alternative. Instead of exceptions being raised, they're returned. Cool.
Tuesday, February 12, 2019
On the uselessness of Enum -- wait, what?
Had a question about an enumerated set of constant values.
"Where do I put these constants?" they asked. It was clear what they wanted. This is another variation on their personal quest which can be called "I want Python to have CONST or Final." It's kind of tedious when a person asks -- repeatedly -- for a feature that's not present in the form they want it.
"Use Enum," I said.
"Nah," they replied. "It's Yet Another Abstraction."
Wait, what?
This is what I learned from rest of their nonsensical response: There's an absolute upper bound on abstractions, and Enum is one abstraction too many. Go ahead count them. This is too many.
Or.
They simply rejected the entire idea of learning something new. They wanted CONST or Final or some such. And until I provide it, Python is garbage because it doesn't have constants. (They're the kind of person that needs to see CONST minutes_per_hour = 60 in every program. When I ask why they don't also insist on seeing CONST one = 1 they seem shocked I would be so flippant.)
YAA. Seriously. Too many layers.
As if all of computing wasn't a stack of abstractions on top of stateful electronic circuits.
"Where do I put these constants?" they asked. It was clear what they wanted. This is another variation on their personal quest which can be called "I want Python to have CONST or Final." It's kind of tedious when a person asks -- repeatedly -- for a feature that's not present in the form they want it.
"Use Enum," I said.
"Nah," they replied. "It's Yet Another Abstraction."
Wait, what?
This is what I learned from rest of their nonsensical response: There's an absolute upper bound on abstractions, and Enum is one abstraction too many. Go ahead count them. This is too many.
Or.
They simply rejected the entire idea of learning something new. They wanted CONST or Final or some such. And until I provide it, Python is garbage because it doesn't have constants. (They're the kind of person that needs to see CONST minutes_per_hour = 60 in every program. When I ask why they don't also insist on seeing CONST one = 1 they seem shocked I would be so flippant.)
YAA. Seriously. Too many layers.
As if all of computing wasn't a stack of abstractions on top of stateful electronic circuits.
Tuesday, February 5, 2019
Python Enhancement Proposal -- Floating an Idea
Consider the following code
It's somewhat less clear in this case that the else: is impossible. A little more algebra is required to create a necessary proof.
The core argument here is Edge Cases Are Inevitable. While we can try very assiduously to prevent them, they seem to be an emergent feature of complex software. There are two arguments that seem to indicate the inevitability of edge and corner cases:
def max(m: int, n: int) -> int:
if m >= n:
return m
elif n >= m:
return n
else:
raise Exception(f"Design Error: {vars()}")
There's a question about else: clause and the exception raised there.- It's impossible. In this specific case, a little algebra can provide that it's impossible. In more complex cases, the algebra can be challenging. In some cases, external dependencies may make the algebra impossible.
- It's needless in general. An else: would have been better than the elif n >= m:. The problem with else: is that a poor design, or poor coordination with the external dependencies, can lead to undetectable errors.
def ackermann(m: int, n: int) -> int:
if m < 0 or n < 0:
raise ValueError(f"{m} and {n} must be non-negative")
if m == 0:
return n + 1
elif m > 0 and n == 0:
return ackermann(m - 1, 1)
elif m > 0 and n > 0:
return ackermann(m - 1, ackermann(m, n - 1))
else:
raise Exception(f"Design Error: {vars()}")
It's somewhat less clear in this case that the else: is impossible. A little more algebra is required to create a necessary proof.
The core argument here is Edge Cases Are Inevitable. While we can try very assiduously to prevent them, they seem to be an emergent feature of complex software. There are two arguments that seem to indicate the inevitability of edge and corner cases:
- Scale. For simple cases, with not too many branches and not too many variables, the algebra is manageable. As the branches and variables grow, the analysis becomes more difficult and more subject to error.
- Dependencies. For some cases, this kind of branching can be refactored into a polymorphic class hierarchy, and the decision-making superficially simplified. In other cases, there are multiple, disjoint states and multiple conditions related to those states, and the reasoning becomes more prone to errors.
The noble path is to use abstraction techniques to eliminate them. This is aspirational in some cases. While it's always the right thing to do, we need to check our work. And testing isn't always sufficient.
The noble path is subject to simple errors. While we can be very, very, very, very careful in our design, there will still be obscure cases which are very, very, very, very, very subtle. We can omit a condition from our analysis, and our unit tests, and all of our colleagues and everyone reviewing the pull request can be equally snowed by the complexity.
We have two choices.
- Presume we are omniscient and act accordingly: use else: clauses as if we are incapable of error. Treat all complex if-elif chains as if they were trivial.
- Act more humbly and try to detect our failure to be omniscient.
If we acknowledge the possibility of a design error, what exception class should we use?
- RuntimeError. In a sense, it's an error which didn't occur until we ran the application and some edge case cropped up. However. The error was *always* present. It was a design error, a failure to be truly omniscient and properly prove all of our if-elif branches were complete.
- DesignError. We didn't think this would happen. But it did. And we need debugging information to see what exact confluence of variables caused the problem.
I submit that DesignError be added to the pantheon of Python exceptions. I'm wondering if I should make an attempt to write and submit a PEP on this. Thoughts?
Tuesday, January 29, 2019
Eager and Lazy Properties
See this
My answer was -- frankly -- vague. Twitter being what it is, I should have written the blog post first and linked to it.
The use case is this.
We've got a property where the returned value is already an instance variable.
I'm not a fan.
This reflects an eager computation strategy. f(x) was computed eagerly and the value made available via a property. One can justify the use of a property to make the value read-only, but... still nope.
There are a lot of alternatives that make more sense to me.
It's read-only because -- really -- if you change it, you break the class. So don't change it.
This is my favorite. Read-onlyness is sometimes described has a way protect utter idiots from breaking a library they don't seem to understand. Or. It's described as a way to prevent some Evil Genius Programmer (EGP) from doing something intentionally malicious and breaking things.
Bah.
It's Python. They have access to the source. Why mess around breaking things this way?
This seems to hit at the original intent without an explicit cached variable. Instead the caching is pushed off into another space. (I'm writing a chapter on decorators, so this may be a bit much.)
The idea, though, is to make properties lazy. If they're expensive, then the result should be cached.
There may be other choices, but I think lazy and eager cover the bases. I don't think eager is wrong, but I don't see the need for a property to hide the attribute created by an eager computation.
Dear Pythonista lazyweb: If I have a property spam and the attribute that backs it is _spam, what do we call that? The "backing attribute"? The "original property"? Something else? Is there an official term for this?— Al Sweigart (@AlSweigart) January 29, 2019
My answer was -- frankly -- vague. Twitter being what it is, I should have written the blog post first and linked to it.
The use case is this.
class X:
def __init__(self, x):
self._value = f(x)
@property
def value(self):
return self._value
We've got a property where the returned value is already an instance variable.
I'm not a fan.
This reflects an eager computation strategy. f(x) was computed eagerly and the value made available via a property. One can justify the use of a property to make the value read-only, but... still nope.
There are a lot of alternatives that make more sense to me.
Option 1. We're All Adults Here.
Here's an approach I think is better.class X:
def __init__(self, x):
self.value = f(x)
It's read-only because -- really -- if you change it, you break the class. So don't change it.
This is my favorite. Read-onlyness is sometimes described has a way protect utter idiots from breaking a library they don't seem to understand. Or. It's described as a way to prevent some Evil Genius Programmer (EGP) from doing something intentionally malicious and breaking things.
Bah.
It's Python. They have access to the source. Why mess around breaking things this way?
Option 2. Lazyiness
Here's an approach that hits at the essential feature.class X:
def __init__(self, x):
self.x = x
@property
@lru_cache(None)
def value(self):
return f(self.x)
This seems to hit at the original intent without an explicit cached variable. Instead the caching is pushed off into another space. (I'm writing a chapter on decorators, so this may be a bit much.)
The idea, though, is to make properties lazy. If they're expensive, then the result should be cached.
There may be other choices, but I think lazy and eager cover the bases. I don't think eager is wrong, but I don't see the need for a property to hide the attribute created by an eager computation.
Things that start badly
Today's Example of Starting Badly: Building HTML.
The code has a super-simple email message with
For a moment, I considered suggesting that f-string substitution wasn't a good long-term solution, since it doesn't cover anything more than the most trivial case.
Two things stopped me from complaining:
f"<html><body><p>stuff {data}</p></body></html>". It was jammed into an email object along with the text version. All very nice.For a moment, I considered suggesting that f-string substitution wasn't a good long-term solution, since it doesn't cover anything more than the most trivial case.
Two things stopped me from complaining:
- The case really was trivial.
- It's administrative code: it sends naggy reminder emails periodically. Why over-engineer it?
What an idiot I was.
Today, the
{data} has been replaced with a complex table instead of a summary. (Why? The user story evolved. And we needed to replace the summary with details.)
The engineer was pretty sure they could use
I should have commented "Don't build HTML that way, it's a bad way to start" on the previous release.
htmlify(data) or data.htmlify() to transform the data into an HTML structure without seriously breaking the f-string nature of the app.I should have commented "Don't build HTML that way, it's a bad way to start" on the previous release.
The f-string solution turns rapidly into complexities layered on complexities dusted over the top with sprinkles of NOPE.
There's a step function change in the app's perceived "complexity". Instead of a simple f-string, we now have to populate a template. It goes from one line of code to more than one (three seems typical.) And. The file-system loader for templates seems more appropriate rather than hard-coding the template in the body of the code. So there are now more files in the app with the HTML templates in them.
However. The Jinja
Lessons learned.
Don't let the currently superficial trivial case slide past without at least a warning. Make the suggestion that functions like "get template" and "populate template" will be necessary even for trivial f-string or string.Template processing.
HTML isn't a first-class part of anything. It's external serialization. Yes, it's for people, but it's only serialization. Serialization has to be separated from the other aspects of the data gathering, map-reduce summarization, and email distribution. There's a pipeline of steps there and the final app should reflect the complete separation of these concerns. Even if it is admin overhead.
However. The Jinja
{{variable|round(2)}} was an immediate victory. The use of {%for%} to build the HTML table was the goal, and that simplification was worth the price of entry. Now we're arguing over CSS nuances to get the columns to look "right."Lessons learned.
Don't let the currently superficial trivial case slide past without at least a warning. Make the suggestion that functions like "get template" and "populate template" will be necessary even for trivial f-string or string.Template processing.
HTML isn't a first-class part of anything. It's external serialization. Yes, it's for people, but it's only serialization. Serialization has to be separated from the other aspects of the data gathering, map-reduce summarization, and email distribution. There's a pipeline of steps there and the final app should reflect the complete separation of these concerns. Even if it is admin overhead.
Subscribe to:
Posts (Atom)